Suivez-nous sur Mastodon

|
|
|
0,
A,
B,
C,
D,
E,
F,
G,
H,
I,
J,
K,
L,
M,
N,
O,
P,
Q,
R,
S,
T,
U,
V,
W,
X,
Y,
Z,
ALL
|
|
0,
A,
B,
C,
D,
E,
F,
G,
H,
I,
J,
K,
L,
M,
N,
O,
P,
Q,
R,
S,
T,
U,
V,
W,
X,
Y,
Z
|
|
0,
A,
B,
C,
D,
E,
F,
G,
H,
I,
J,
K,
L,
M,
N,
O,
P,
Q,
R,
S,
T,
U,
V,
W,
X,
Y,
Z
|
|
A propos d'Obligement

|
|
David Brunet

|
|
|
|
En pratique : Utilisation de Yacc (compilation de l'exemple)
(Article écrit par Pascal Amiable et extrait d'Amiga News Tech - mars 1992)
|
|
Nous continuons notre étude de Yacc avec d'une part, la synthèse du programme du
mois dernier et sa compilation,
et d'autre part, son interfaçage avec Flex, l'analyseur lexical.
Comme je vous l'ai signalé le mois dernier, Yacc est disponible dans le domaine public,
et plus particulièrement sur la disquette Fred Fish numéro 419.
Vous trouverez outre l'exécutable du programme, les sources compactés avec LhArc, ainsi qu'un fichier
documentation des plus succincts, puisqu'il se borne à décrire la syntaxe d'utilisation de la commande.
En prenant la peine de décompacter ces sources, vous trouverez un répertoire "Test" qui contient le
source Yacc complet de la commande FTP (pour File Transfert Protocol), commande permettant la gestion
des transferts de données dans un réseau.
L'installation de Yacc est des plus simples, puisque seul l'exécutable est nécessaire au bon fonctionnement du
produit. Il vous suffit donc de posséder Yacc dans votre répertoire courant ou dans un répertoire accessible
soit directement (comme C:) soit à l'aide d'un chemin d'accès réalisé grâce à la commande "Path".
Compilation de l'exemple
Première chose à faire, récapituler l'exemple du mois dernier disséminé tout le long de l'article,
suite aux explications le concernant.
Le programme Yacc est donc le suivant :
Rappelons que les symboles "%%" séparent les trois sections du programme (déclarations, règles, fonctions
utilisateur). Je vous conseille de laisser une ligne blanche après le "%%" séparant les règles des fonctions
utilisateur : Yacc a en effet une fâcheuse tendance à ne pas reconnaître ce symbole lors de la compilation.
La compilation Yacc du programme, une fois celui-ci tapé et sauvegardé avec une extension ".y",
s'effectue sans encombre. La commande est la suivante : "yacc exemple.y".
Yacc génère alors un fichier dénommé "y.tab.c" d'environ 8 ko, représentant le programme que vous avez
décrit en quelques lignes (ce programme ne sera pas listé ici mais je vous conseille de l'étudier par vous-même).
Dès lors, il ne reste plus qu'à compiler ce fichier source C à l'aide de votre compilateur favori, par exemple
le SAS/Lattice C, en tapant "lc -Lc y.tab.c". L'exécutable généré, à savoir "y.tab", peut être lancé dès ce
stade. Mais comme vous pourrez le remarquer, les résultats obtenus sont invariablement 'Erreur de Syntaxe ".
C'est tout à fait normal, puisque la partie d'analyse lexicale n'a pas encore été réalisée.
Comment Yacc fonctionne-t-il ?
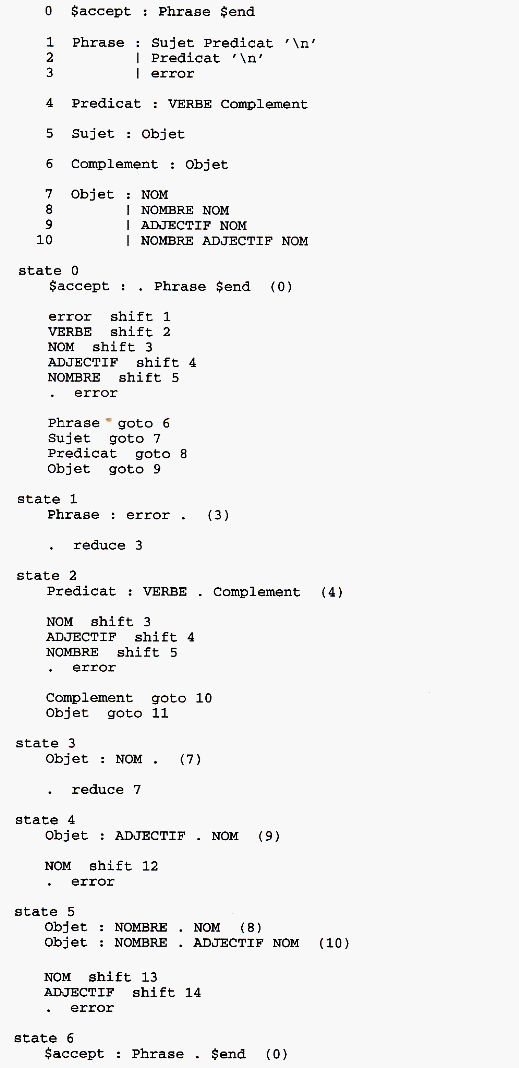
Pour réaliser cette étude, nous allons utiliser l'option "-v" (pour verbose) qui va générer un fichier "y.output"
contenant le fichier descripteur de la logique du programme avant sa transcription en C. Il suffit de taper "yacc -v exemple.y".
Le fichier résultant est le suivant :
Ce fichier est la description de ce que l'on appelle une "machine à états finis" comportant 19 états.
Une machine à états finis est un programme pouvant prendre un nombre fini d'états possibles, en fonction des données
d'entrées. Un tel programme ne peut donc jamais se retrouver dans un état imprévisible qui le conduirait à un
défaut de fonctionnement. Dans le cas d'analyseurs syntaxiques, l'intérêt est évident puisque l'on ne sait jamais
quels peuvent être les réponses de l'utilisateur.
Si nous étudions ce listing en détail, nous nous apercevons que les règles que nous avons définies dans le source
Yacc sont toutes reprises dans cet état sous la forme d'un numéro entre parenthèses. Par exemple :
...est bien la règle numéro 1.
Chaque état de l'analyseur est défini en termes de progrès par rapport à l'état précédent. A chaque fois que l'analyseur
sémantique reçoit un symbole de l'analyseur lexical, il essaye de le faire coïncider avec un symbole de la partie
droite de la définition de chaque état.
Lorsqu'il trouve une correspondance dans une règle, l'analyseur sémantique doit prendre une décision :
- S'il est en mesure à cet instant de reconnaître toute l'expression de droite, deux cas peuvent se présenter :
soit le symbole de gauche est non terminal, et dans ce cas, il réduit cette expression dans l'état de la machine
indiqué par la commande "reduce" (il doit alors attendre des informations supplémentaires pour conclure), soit le
symbole de gauche est terminal, et dans ce cas, l'analyseur a atteint un état terminal de reconnaissance et est
en mesure de donner les résultats associés. C'est-à-dire qu'il va déclencher la fonction C associée à l'état indiqué
par la commande "accept".
- Sinon, il empile cette correspondance et se rend dans l'état suivant indiqué par la commande "shift".
- Dans tous les autres cas, il y a génération d'erreur (commande error).
Suivons ce mécanisme pas à pas sur un exemple, à savoir la dorénavant célèbre phrase "Stéphane range trois disquettes
vertes \n" (ce qui est un exploit de la part de Stéphane). Cette phrase sera convertie par tout bon analyseur syntaxique en :
NOM VERBE NOMBRE ADJECTIF NOM $end.
|
Nous connaissons tous ces symboles, à l'exception de "$end" qui indique tout simplement la fin de la phrase.
L'analyseur syntaxique débute avec cette phrase dans un état (-1,0). Le premier chiffre correspond au symbole
reconnu (aucun pour le moment) et le deuxième, à l'état en cours (ici 0).
Le premier symbole en entrée est "NOM". Associé à l'état 0, il déclenche un "shift"
vers l'état 3. Le couplet (NOM,3) est empilé et l'analyseur pointe maintenant sur l'état 3.
Le symbole suivant, "VERBE", n'est pas reconnu. Par contre, cet état contient une expression de droite
parfaitement connue, ce qui déclenche une opération "reduce". Le couplet (NOM,3) est dépilé, "NUM"
est remplacé par sa valeur réduite (à savoir un Objet) et l'analyseur est renvoyé à l'état 0. Dans cet état,
le terme "Objet" est reconnu comme l'état 9. On empile donc (Objet,9).
Dans l'état 9, le symbole "VERBE" n'est pas reconnu. Par contre, "Objet" déclenche une opération de réduction en
"Sujet". On dépile (Objet,9), on remplace "Objet" par "Sujet" et on retourne en 0. Là, "Sujet"
nous renvoie en 7. On empile donc (Sujet,7).
Dans l'état 7, "VERBE" est reconnu. On va donc en 2, où l'on empile (VERBE,2).
Pile : (-1,0), (Sujet,7), (VERBE,2)
|
"NOMBRE" est reconnu et nous amène dans l'état 5.
Pile : (-1,0), (Sujet,7), (VERBE,2), (NOMBRE,5)
|
Dans cet état, "ADJECTIF" est reconnu, le pointeur est mis sur l'état 14.
Pile : (-1,0), (Sujet,7), (VERBE,2), (NOMBRE,5), (ADJECTIF,14)
|
...et l'état 14 reconnaît "NOM" et déclenche l'état 17.
Pile : (-1,0), (Sujet,7), (VERBE,2), (NOMBRE,5), (ADJECTIF,14), (NOM,17)
|
L'état 17 réduit les trois derniers couplets à l'état d'un Objet. L'état intermédiaire est 2. Dans cet état,
l'Objet nous dirige vers l'état 11, où ce dernier est réduit à l'état de "Complément", déclenchant l'état 10.
Pile : (-1,0), (Sujet,7), (VERBE,2), (Complement,10)
|
L'état 10 réduit l'ensemble "VERBE Complément" en un "Prédicat" dirigeant le pointeur vers 7. Là,
le pointeur devient 15 à cause du goto.
Pile : (-1,0), (Sujet,7), (Predicat,15)
|
En 15, '\n' est analysé ce qui donne :
Pile : (-1,0), (Sujet,7), (Predicat,15), ('\n',18)
|
En 18, il y a réduction de l'expression en une phrase et pointage sur l'état 0.
En zéro, le déclenchement de "accept" signifie l'exécution du source C associé à la règle déclenchée, en l'occurrence
(0), soit l'impression de "Phrase Déclarative\n".
Comme vous pouvez le voir, c'est certes fastidieux, mais, au fond, très simple. Je vous laisse imaginer, à la vue de
cet exemple le nombre de règles déclenchées dans un analyseur syntaxique complexe sans transition, nous allons maintenant
passer à la deuxième partie de cet article, à savoir l'interfaçage entre Lex et Yacc.
Lex et Yacc : un mariage heureux
Nous allons maintenant utiliser Lex pour créer la partie analyse lexicale
de notre programme d'exemple. Les programmes Lex, je vous le rappelle, sont assez similaires aux programmes
Yacc possédant en cela des règles pour reconnaître des mots et retourner les symboles associés.
Un programme Lex se compose de trois parties : une section définitions, une section règles et une section
sous-programmes.
La section "Règles" se compose d'une table d'expressions auxquelles sont associées des actions, actions qui sont
effectuées lorsque le mot en entrée satisfait les conditions requises dans l'expression.
Pour de plus amples informations sur Lex (FLex sur Amiga), je vous renvoie à l'article de
l'Amiga News Tech Numéro 28 concernant ce produit. Rappelons simplement que
FLex est disponible sur la disquette Fred Fish n°412.
Le petit programme Lex qui va être associé à notre programme Yacc va être en mesure de retrouver les symboles suivants :
- NOM : Christine, Stéphane, Anne, disquette(s), article(s).
- ADJECTIF : Vert(e)(s), Rouge(s), Petit(es).
- VERBE : Prend, Range, Donne.
- NOMBRE : de un à dix, Le, La.
A chaque fois que Lex trouvera une de ces occurrences (ou un dérivé tel Vert et Verte), il déclarera ce qu'il
a trouvé et retournera le symbole associé (dans l'exemple, ADJECTIF). C'est une tâche assez simple à réaliser,
n'est-ce pas ?
|