Suivez-nous sur X

|
|
|
0,
A,
B,
C,
D,
E,
F,
G,
H,
I,
J,
K,
L,
M,
N,
O,
P,
Q,
R,
S,
T,
U,
V,
W,
X,
Y,
Z,
ALL
|
|
0,
A,
B,
C,
D,
E,
F,
G,
H,
I,
J,
K,
L,
M,
N,
O,
P,
Q,
R,
S,
T,
U,
V,
W,
X,
Y,
Z
|
|
0,
A,
B,
C,
D,
E,
F,
G,
H,
I,
J,
K,
L,
M,
N,
O,
P,
Q,
R,
S,
T,
U,
V,
W,
X,
Y,
Z
|
|
A propos d'Obligement

|
|
David Brunet

|
|
|
|
Programmation : Assembleur - Routine de délai matériel
(Article écrit par Loïc Far et extrait d'Amiga News Tech - novembre 1991)
|
|
Quelques abonnés ont été déçus de ne pas trouver, dans mon article
traitant des lecteurs de disquette, la routine promise de délai matériel (à grands coups de CIA)
permettant de temporiser le déplacement de la tête de lecture de piste à piste. D'autres, plus mesquins,
auraient souhaité trouver plus d'informations d'une part sur le codage MFM, d'autre part sur l'utilisation du
Blitter pour le décodage des données.
A tous ceux-là, je tiens d'abord à adresser mes excuses les plus plates, à défaut des plus sincères, et
à rappeler ce que j'avais alors dit dans : décoder le format MFM au Blitter relève à mon avis de l'hérésie.
Cela revient à se limiter volontairement à charger des données en mémoire Chip, alors qu'en utilisant le
68000, on peut utiliser un tampon mémoire de piste se trouvant n'importe où en mémoire. De plus, du fait
du délai nécessaire au moteur pas à pas pour déplacer la tête de lecture/écriture, le temps gagné serait tout
de suite perdu à attendre que celle-ci soit effectivement positionnée sur la piste suivante. Sans oublier que
le Blitter peut toujours être utilisé pour autre chose pendant ce temps-là, par exemple pour une animation
graphique pendant le chargement. Enfin, il faut bien reconnaître ce qui est, le décodage MFM est beaucoup plus
facile à réaliser au 68000 !
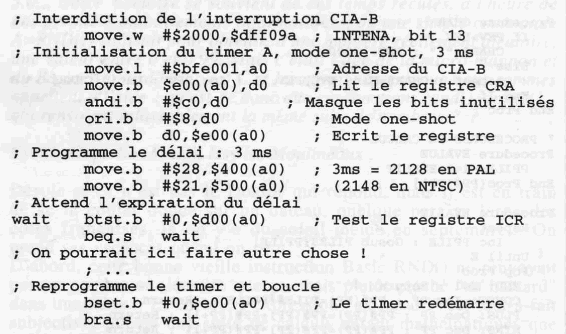
Cela dit, voici un tout petit bout de programme assembleur qui initialise le chronomètre A du CIA B
et compte exactement tous les trois millisecondes, soit le temps minimum recommandé par les ingénieurs
de chez Commodore Amiga. Cet exemple ne fonctionne pas tel quel, et il vous faudra l'insérer correctement
dans le programme se trouvant dans cet article.
Voilà, ce n'était vraiment pas grand-chose, et je m'en veux de ne pas l'avoir tout de suite fait dans le programme concerné.
MFM
Vous les aviez demandées, voici quelques informations complémentaires sur le format MFM et sur la manière dont
l'Amiga enregistre ses pistes et secteurs sur la disquette. D'abord, le format MFM lui-même. Rappelons que
ce format est destiné à éviter toute erreur de synchronisation lors de la lecture et de l'écriture des données,
en insérant un bit de synchronisation entre chaque bit de donnée. Qui plus est, on code d'abord les bits impairs
puis ensuite les bits pairs, dans deux tampons mémoire consécutifs en mémoire.
Donc, pour décoder un bloc de données, il suffit d'utiliser la routine suivante :
Le codage est beaucoup plus délicat et ne sera pas abordé maintenant. Si vraiment vous désirez savoir
comment procéder, écrivez-moi des tonnes de lettres, j'adore me faire injurier. J'avoue humblement
ne m'être jamais attaqué à ce côté du problème mais qui sait, avec un peu de bonne volonté, on arrive à tout.
Un mot de synchronisation particulier est placé devant chaque secteur, qui permet au DMA d'en reconnaître
exactement le début. Ce mot est une valeur MFM bidon, c'est-à-dire qui ne correspond à aucun codage possible (de
cette manière, on est sûr qu'il s'agit bien d'une marque de synchronisation et non d'une donnée du secteur).
AmigaDOS utilise le mot $4489, mais n'importe quel autre mot "bidon" ferait tout aussi bien l'affaire.
Les pistes
Une piste contient 11 secteurs constitués d'une zone d'informations diverses de 32 octets suivis d'une zone
de données de 512 octets. La piste elle-même est précédée d'un GAP d'environ 700 octets. Je dis "environ"
parce que sa taille peut varier suivant la position de la piste (près du centre ou au contraire de l'extérieur)
sur la disquette. Le GAP lui-même ne sert strictement à rien pour le DOS, mais permet d'éviter, à l'écriture
de la piste, que les dernières données écrites n'écrasent les premières (n'oubliez pas qu'une piste est
circulaire !). Si on additionne tout ceci, on obtient une longueur de 700+(2*(11*(32+512)))=12 668
octets MFM par piste.
Voici résumé dans un tableau le format exact d'un secteur codé.
| Décalage |
Valeur |
Signification |
| 0 |
$aaaa |
Premier mot du secteur |
| 2 |
$aaaa |
Second mot du secteur |
| 4 |
$4489 |
Premier mot du synchronisation |
| 6 |
$4489 |
Second mot de synchronisation |
| 8 |
xxxxx |
ID secteur (bits impairs) |
| 12 |
xxxxx |
ID secteur (bits pairs) |
| 16 |
xxxxx |
Données AmigaDOS (bits impairs) |
| 32 |
xxxxx |
Données AmigaDOS (bits pairs) |
| 48 |
xxxxx |
Somme de contrôle de l'entête (bits impairs) |
| 52 |
xxxxx |
Somme de contrôle de l'entête (bits pairs) |
| 56 |
xxxxx |
Somme de contrôle des données (bits impairs) |
| 60 |
xxxxx |
Somme de contrôle des données (bits pairs) |
| 64 |
xxxxx |
Données (bits impairs) |
| 576 |
xxxxx |
Données (bits pairs) |
Comme on le voit, si l'on veut décoder tout ça, il faut procéder en quatre étapes : d'abord l'ID
secteur, ensuite la somme de contrôle de l'entête, puis la somme de contrôle
des données, et enfin les données elles-mêmes. La routine MFMUncode du programme de
l'article du n°25
gérait tout cela et vérifiait en même temps la validité des deux sommes de contrôle.
|